Android 系统/手机 有哪些好?
碎片化
❤️ 24💬 6
碎片化
这是在黑 Kotlin 么。。
Kotlin 过去可不是为了成为 Java8 的取代物而生的(更不是为了 Android 而生,而且要知道 Kotlin 比 Java8 还早出世),它和 Scala,Groovy 等 JVM 语言一样都不是基于 Java 本身语法的拓展,所以它是一门新的语言。它包含了 FP 的思想,支持创建 DSL,有着类 Swift 的安全类型,还有 Extension 等语法糖,更重要的是不用写分号了_(°ω°」 ∠),这是有历史包袱的 Java,Java8 达不到的。
当然,Java8 肯定也会解救更大一票的 Android 开发者,至少不用再为没法使用 Lambda 而伤心了(手码字,逃
Java 是最贴近 JVM 的语言,只要在对性能还有要求的情况下,Java 依旧是 JVM 上的首选。
事实上在对任何语言进行选择时,都是基于对运行效率和开发效率之间的权衡。所以在我看来 Kotlin 是不可能取代 Java 的(官方也从未立意过要取代),但表达能力更强的 Kotlin 在一些地方肯定会比 Java 更适合,例如一些更高层的逻辑。我觉得就会像 Unity3D 引擎用 C/C++ 来写,但是游戏逻辑会选择用 C# 一样。
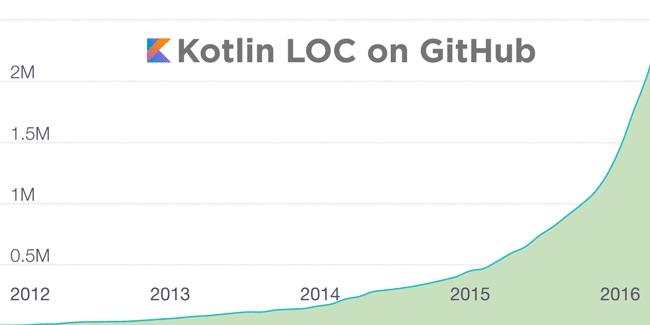
Kotlin 是匹脱缰的黑马,现在已经攀升到 1.0 正式版了!官方统计数据表明,已经有越来越多使用 Kotlin 进行开发的项目,而最流行的一些 Android 项目也都开始尝试使用 Kotlin 来进行构建了。
为了让你尽快体验一番 Kotlin 的魅力,Kotgo 诞生了!现在可以通过在终端输入下面一行命令来为你生成使用 MVP 架构的,包含各种流行库的 Kotlin 模板项目,你可以直接使用 Android Studio 打开它:
python -c "$(curl -fsSL https://raw.githubusercontent.com/nekocode/kotgo/master/project_creator.py)"
欢迎开发者们对 Kotlin 进行尝试!也欢迎朋友们 PR 以及 Star ,这对 Kotlin 的推广十分给力。
谢邀。一个比较不错的解决方案:
chrisjenx/Calligraphy · GitHub
Custom font in Styles
<style name="TextViewCustomFont"> <item name="fontPath">fonts/RobotoCondensed-Regular.ttf</item> </style>Custom font defined in Theme
<style name="AppTheme" parent="android:Theme.Holo.Light.DarkActionBar"> <item name="android:textViewStyle">@style/AppTheme.Widget.TextView</item> </style> <style name="AppTheme.Widget"/> <style name="AppTheme.Widget.TextView" parent="android:Widget.Holo.Light.TextView"> <item name="fontPath">fonts/Roboto-ThinItalic.ttf</item> </style>
上面的 Styles 配置,可以方便地把应用内所有 TextView 的字体配置为「Roboto-ThinItalic」(需要字体文件支持)。但是需要对 Activity 做一些 Wrap:
@Override protected void attachBaseContext(Context newBase) { super.attachBaseContext(CalligraphyContextWrapper.wrap(newBase)); }
大部分答主都讲出原因了。我解释下为什么会要求只在 UI 线程修改 UI:
绝大部分 GUI 系统都是只允许「单个线程对某块区域做绘制操作的」,例如在 Windows 和 Android 系统下都把这块区域叫做 Window。如果允许多个线程对同一块区域做绘制的话,很有可能导致某个线程还没绘制完,另一个线程上一些依赖之前绘制结果的操作出问题,例如 Alpha 混合。除非加锁,然而加锁更慢还不如单线程。
近两天开始系统地接触 RxJava。在没接触它之前,所有数据是以「多个函数顺序处理」的形式来进行加工,而且一旦某些中间步骤需要进行异步处理,代码将变成各种 Callback Hell。
RxJava 可以消灭各种 Callback Hell,它提供了异步处理数据的绝佳方式,但是它的亮点绝对不仅仅在于异步处理上,它最大的亮点在于 操作符,它提供了对数据流进行各种抽象加工的操作符。
想要在程式中很好的贯彻 RxJava,你就需要明白「一切皆流」的道理,我在 baseframework 里创建了一个简单的例子,使用 Retrofit 进行网络接口调用,并通过 RxJava 对数据流进行处理:
object WeatherModule {
data class WeatherWrapper(@SerializedName("weatherinfo") val weather: Weather)
fun getWeather(cityId: String): Observable<Weather> =
Net.api.getWeather(cityId).subscribeOn(Schedulers.io())
.map { it.weather }
.doOnEach {
if(it.kind == Notification.Kind.OnNext) {
// Cache weather to local cache
Local["weather"] = it.value
}
}
.onErrorResumeNext {
// Fetech weather from local cache
val weather: Weather? = Local["weather"]
Observable.just(weather)
}
}
我使用 RxJava 对接口返回的数据进行了一些处理:
可以看出,这种链式调用配合 Kotlin 的 lambda 表达,真的是无比优雅惬意。
近几天的学习积累了一些琐碎的东西,与抽空更了 kotlin_android_base_framework ,我对 Kotlin 以及一些库进行了更新,并对 Model Layer 进行了一些修改,它看起来变成了这样:
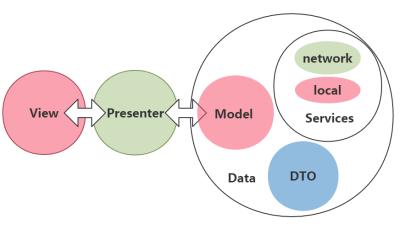
在 baseframework 里面,RxJava Stream 几乎是不同层(例如 Module Layer 和 Presenter Layer)间最好的交互方式,它能够对数据进行加工、变换,甚至传递错误。例如在 Module Layer 中,我们在 RxJava Stream 中进行各种业务逻辑、数据交并处理,最后只需变换成 DTO Stream 传回 Presenter Layer 即可。
RxJava 是我认为除去 Kotlin 外对开发最能提高效率的工具,建议读者们都能学习一番。
转行做投资人,实现财务自由,找个高层次圈子内的老婆,过美滋滋的生活。
投入大量资本去做「自己想做的产品」,建立下一个能 IPO 的企业。
一觉梦醒。。。继续搬砖去
由于一些原因,之前并不知道 Kotlin 发布了新版本,在上班第一天才得知这个振奋人心的消息。Kotlin 的这次更新有着重要意义,它意味着离官方发布 1.0 最终释放版已经很近了!
在 Kotlin 1.0 Release Candidate is Out! 中可以查看英文原文,伴随着这次更新,Anko,KotterKnife 等 Lib 也进行了迭代。当然,我对 base_framework 也进行了更新(是个兴奋的过程)。
这次更新,语法上并没有太大的改动,Stdlib 有略微的修改,但最主要的工作还是在 Bug Fixing 以及 IDE Plugin 的优化上,下面我将抽重点说下。
语法变得更为干净:
新版本还能够使用 @delegate: 对 Delegate Fields 进行注解。例如,下面这段代码将 foo 注解为 Transient:
class Example {
@delegate:Transient
val foo by Lazy { ... }
}
此外,该次更新还支持在编译期对 使用点变型(Use-site Variance)进行类型检测,所谓使用点变型,就是下面代码中的 MutableList
val list: MutableList<out Any> = mutableListOf(1, 2, 3)
对 Use-site Variances 进行类型检测,导致在编译下面代码的时候会报错:
val ints = mutableListOf(1, 2, 3)
val strs = mutableListOf("abc", "def")
val comps: MutableList<out Comparable<*>> = ints
comps.addAll(strs) // ?! Adding strings to a list of ints
编译器会拒绝编译最后一行,并提示:
Projected type MutableList<out Comparable<*» restricts the use of addAll()
要注意的是,就算 strs 和 ints 同样是 MutableList
另外在 Android Extensions 和 IDE 上都有些改变,详情可查看原文。使用 IntelliJ IDEA 而非 Android Studio 的用户,需要手工下载 Plugin 并安装才能成功升级,下载地址也请看原文。
Kotlin 让人越来越看到希望,在不久的将来,Kotlin 将重拳出击!o(*≧▽≦)ツ

很小的时候就一直有在接触编程了,但正式开始写第一个意义上的程序,是在读初三的时候。到目前为止,刚好写了有十年。按照时间前后排序,学过的语言有 ActionScript、VB、C++、Lua、Java、Python、Kotlin。感受是,读书时能经常在同学面前显摆,例如给课堂讲座上的电脑写上「病毒」,在同座的文曲星上写游戏解闷,大学时因为写代码厉害泡到了前女友,工作时又因为起步比别人早,拿到了很多便利。
这是个传奇的故事!做过 ACM 的人大概都知道:
Quake-III Arena (雷神之锤3)是90年代的经典游戏之一。该系列的游戏不但画面和内容不错,而且即使计算机配置低,也能极其流畅地运行。这要归功于它3D引擎的开发者约翰-卡马克(John Carmack)。事实上早在90年代初DOS时代,只要能在PC上搞个小动画都能让人惊叹一番的时候,John Carmack就推出了石破天惊的Castle Wolfstein, 然后再接再励,doom, doomII, Quake…每次都把3-D技术推到极致。他的3D引擎代码资极度高效,几乎是在压榨PC机的每条运算指令。当初MS的Direct3D也得听取他的意见,修改了不少API。
最近,QUAKE的开发商ID SOFTWARE 遵守GPL协议,公开了QUAKE-III的原代码,让世人有幸目睹Carmack传奇的3D引擎的原码。这是QUAKE-III原代码的下载地址:
http://www.fileshack.com/file.x?fid=7547(下面是官方的下载网址,搜索 “quake3-1.32b-source.zip” 可以找到一大堆中文网页的。ftp://ftp.idsoftware.com/idstuff/source/quake3-1.32b-source.zip) )
我们知道,越底层的函数,调用越频繁。3D引擎归根到底还是数学运算。那么找到最底层的数学运算函数(在game/code/q_math.c), 必然是精心编写的。里面有很多有趣的函数,很多都令人惊奇,估计我们几年时间都学不完。在game/code/q_math.c里发现了这样一段代码。它的作用是将一个数开平方并取倒,经测试这段代码比(float)(1.0/sqrt(x))快4倍:
float Q_rsqrt( float number ) { long i; float x2, y; const float threehalfs = 1.5F; x2 = number * 0.5F; y = number; i = * ( long * ) &y; // evil floating point bit level hacking i = 0x5f3759df - ( i >> 1 ); // what the fuck? y = * ( float * ) &i; y = y * ( threehalfs - ( x2 * y * y ) ); // 1st iteration // y = y * ( threehalfs - ( x2 * y * y ) ); // 2nd iteration, this can be removed #ifndef Q3_VM #ifdef __linux__ assert( !isnan(y) ); // bk010122 - FPE? #endif #endif return y; }函数返回1/sqrt(x),这个函数在图像处理中比sqrt(x)更有用。
注意到这个函数只用了一次叠代!(其实就是根本没用叠代,直接运算)。编译,实验,这个函数不仅工作的很好,而且比标准的sqrt()函数快4倍!要知道,编译器自带的函数,可是经过严格仔细的汇编优化的啊!
这个简洁的函数,最核心,也是最让人费解的,就是标注了“what the fuck?”的一句
i = 0x5f3759df - ( i » 1 );再加上y = y * ( threehalfs - ( x2 * y * y ) );
两句话就完成了开方运算!而且注意到,核心那句是定点移位运算,速度极快!特别在很多没有乘法指令的RISC结构CPU上,这样做是极其高效的。算法的原理其实不复杂,就是牛顿迭代法,用x-f(x)/f’(x)来不断的逼近f(x)=a的根。
没错,一般的求平方根都是这么循环迭代算的但是卡马克(quake3作者)真正牛B的地方是他选择了一个神秘的常数0x5f3759df 来计算那个猜测值,就是我们加注释的那一行,那一行算出的值非常接近1/sqrt(n),这样我们只需要2次牛顿迭代就可以达到我们所需要的精度。好吧如果这个还不算NB,接着看:
普渡大学的数学家Chris Lomont看了以后觉得有趣,决定要研究一下卡马克弄出来的这个猜测值有什么奥秘。Lomont也是个牛人,在精心研究之后从理论上也推导出一个最佳猜测值,和卡马克的数字非常接近, 0x5f37642f。卡马克真牛,他是外星人吗?
传奇并没有在这里结束。Lomont计算出结果以后非常满意,于是拿自己计算出的起始值和卡马克的神秘数字做比赛,看看谁的数字能够更快更精确的求得平方根。结果是卡马克赢了… 谁也不知道卡马克是怎么找到这个数字的。
最后Lomont怒了,采用暴力方法一个数字一个数字试过来,终于找到一个比卡马克数字要好上那么一丁点的数字,虽然实际上这两个数字所产生的结果非常近似,这个暴力得出的数字是0x5f375a86。
Lomont为此写下一篇论文,“Fast Inverse Square Root”。 论文下载地址:
http://www.math.purdue.edu/~clomont/Math/Papers/2003/InvSqrt.pdf
http://www.matrix67.com/data/InvSqrt.pdf参考:<IEEE Standard 754 for Binary Floating-Point Arithmetic>
最后,给出最精简的1/sqrt()函数:
float InvSqrt(float x) { float xhalf = 0.5f*x; int i = *(int*)&x; // get bits for floating VALUE i = 0x5f375a86- (i>>1); // gives initial guess y0 x = *(float*)&i; // convert bits BACK to float x = x*(1.5f-xhalf*x*x); // Newton step, repeating increases accuracy return x; }大家可以尝试在PC机、51、AVR、430、ARM、上面编译并实验,惊讶一下它的工作效率。
前两天有一则新闻,大意是说 Ryszard Sommefeldt 很久以前看到这么样的一段 code (可能出自 Quake III 的 source code):
float InvSqrt (float x) { float xhalf = 0.5f*x; int i = *(int*)&x; i = 0x5f3759df - (i>>1); x = *(float*)&i; x = x*(1.5f - xhalf*x*x); return x; }他一看之下惊为天人,想要拜见这位前辈高人,但是一路追寻下去却一直找不到人;同时间也有其他人在找,虽然也没找到出处,但是 Chris Lomont 写了一篇论文 (in PDF) 解析这段 code 的算法 (用的是 Newton’s Method,牛顿法;比较重要的是后半段讲到怎么找出神奇的 0x5f3759df 的)。
PS. 这个 function 之所以重要,是因为求 开根号倒数 这个动作在 3D 运算 (向量运算的部份) 里面常常会用到,如果你用最原始的 sqrt() 然后再倒数的话,速度比上面的这个版本大概慢了四倍吧… XD
PS2. 在他们追寻的过程中,有人提到一份叫做 MIT HACKMEM 的文件,这是 1970 年代的 MIT 强者们做的一些笔记 (hack memo),大部份是 algorithm,有些 code 是 PDP-10 asm 写的,另外有少数是 C code (有人整理了一份列表)
看有人拿 XML 和 JSON 做比较,顺便补一点:
XML 是「文档标记语言」,而 JSON 是「数据交互语言」,XML 比起 JSON 描述能力要强,所以在描述复杂文档的时候会选用 XML(例如 Layout 文件)。但是 JSON 比 XML 更为 Human readable、更易编写,也对机器更为友好,所以用 JSON 来储存一些简单的配置是比 XML 要好用得多的(例如大家都知道的 Shadowsocks 就是使用 JSON 进行应用配置)。但是 JSON 天生描述能力不强,它擅长的是描述数据,而非文档(配置其实也是文档的一种),所以稍微复杂的文档是不会使用 JSON 来描述,这也就是为什么会衍生出 YAML、TOML 一类语言的原因(拒绝拥抱 XML 的后果)。
===
SharedPreferences 是一整套东西啊,PreferencesActivity 也依赖于它。所以对实现 APP 偏好设置来说,它就是「最方便的实现」,你不用关心它底层是用数据结构去储存的,只是 Android 选择用 XML 去描述而已。
而 SQLite 是关系数据库,数据间有较复杂关系的,操作需要用到复杂的增删改查,无疑使用 SQLite 是最好的方案。
而题主说的一些轻量的数据,确实是持久化为文件更方便。如果是储存 用户偏好设置 还是用 SharedPreferences 来解决方便多了,无需接触到数据格式。如果并非面向用户,而是面向应用或面向开发者的话(例如一些 应用配置、常用数据),JSON 是不错的选择,毕竟 JSON 比起 XML 来说更易阅读与调试。
当然 JSON 也不是唯一选择,应用配置的话用 YAML 或 TOML 更好(更强的描述能力,更少冗余),只不过 JSON 应用更广泛罢了。
本系列文章将通过解剖 kotlin_android_base_framework 项目,对其中的一些代码进行展开讲解,来挖掘 kotlin 在现实应用中的一些敏捷优雅之处。
本系列文章内容的侧重点是 「 kotlin 在 Android 开发中的实际应用」,通过现实代码来对 kotlin 的一些琐碎知识进行展开。所以作者建议读者,在阅读此系列文章之前先掌握 kotlin 的一些基础知识。
对于「如何在 Android Studio 中加入 kotlin 支持」,以及 kotlin 的一些基础语法,本系列文章不进行系统地讲解,读者可以参考下面两份文档。
在编码界当中,对于绝大部分 Java 公民来讲,要说服他们花学习成本在一门新的语言上并不容易,要推动他们将 kotlin 用在生产环境中更加不容易。
所以在文章开头,请允许我先对该次专栏的主角 kotlin 进行一番介绍,藉此宣扬下「使用 kotlin 代替 Java 进行编码」的想法~
下面,我将列举 kotlin 的语法上的一些先进思想。至于 kotlin 语言本身的一些优势,请参考上一篇文章 #前言# ,这里只谈谈 kotlin 的语法。
kotlin 里的变量定义有两种,val 和 var。其中 val 等同 Java 中 final 修饰的变量(只读)。kotlin 的变量定义支持 赋值时类型推断,且 所有变量默认被修饰为「不可为 null」,必须显式在类型后添加 ? 修饰符才可赋值为 null。
// Java
String strJava = "test"
// Kotlin
val strKot = "test"
var strNullable: String? = null
初次使用 kotlin 的用户可能会不习惯,在 Java 中,大多情况下变量都被定义为 nullable,这样可以通过对其赋值 null ,来表示该变量尚未初始化,或者该变量无数据。
但是这样要付出的代价往往是沉重的,默认类型为 nullable,导致了各种空类型安全问题。Java 代码中很多对外不透明的实现,你根本不知道返回值是否有可能为空,导致很多地方需要繁琐的非空检测,否则很容易触发 runtime error。
而 kotlin 明确地规定了所有类型默认为非空,这样的好处在于「从习惯上解决了空类型安全担忧」,无需频繁地担心变量是否为 null。但相应带来的一些成本就是,在变量初始化(赋值)阶段可能需要多做些功夫。
例如我在写 App.kt 中使用的巧妙的用法 (这里 companion object 代码块内的变量可以看作 Java 中的静态变量,关于 companion object 的介绍在下文会有提到) :
public class App : Application() {
override fun onCreate() {
super.onCreate()
instanceTmp = this
}
companion object {
private var instanceTmp: App? = null
public val instance: App by lazy {
instanceTmp!!
}
}
}
这里通过 lazy delegate 来对 instane 进行懒赋值(直到首次调用再进行赋值),这样,只要保证第一次对 instance 进行访问时 APP 已经实例化,那就可以保证 instance 恒不为空(大多情况下,你在 Android 开发中对Application 的实例进行访问时,该 Application 通常就已经被实例化了)。
形如上面的奇技淫巧还有很多,日后再详细展开说。而对于 nullable 的变量,可以使用 ?. 运算符检验是否为 null,如果为 null 则不运行运算符后的操作。
或者使用 !.运算符来强制访问 nullable 变量的子属性或方法,如果该变量为 null 的话,就在运行时抛出错误:
var strNullable: String? = null
strNullable?.trim()
strNullable!.trim()
总结下。感觉 kotlin 的思想就是,尽量习惯性地将变量设计为 不可为空,这样在后面对该变量的运算中会减少很多问题。
不用再通过匿名对象传递方法,直接支持形如下面的写法:
view.setOnClickListener({
// do something...
})
关于 kotlin 中的匿名类和 lambdas 的具体应用,会在以后的篇幅介绍。
例如下面对于 View 类的拓展:
public val View.ctx: Context
get() = getContext()
进行以上定义后,就可以在所有 View 及其子类内直接访问 ctx 属性来取代调用 getContext(),多么美妙的事情!很多 kotlin 的外部库都依赖这个特性,来生成一些减少编码量的语法糖。
例如 kotlin 默认为已定义的类属性生成 getter,setter,并支持形如下面的语法糖:
// Java
textView.setText("test")
showToast(textView.getText().toString())
// Kotlin
textView.text = "test"
showToast(textView.text.toString())
安利了 kotlin 的一大堆神油后,我们还是回到本系列的核心内容吧。本系列主要对 kotlin 在 Android 开发中的一些敏捷实现进行讲解。上文讲了一些 kotlin 语法上的强大之处,但是难以在这么短的篇幅内将 kotlin 的语法全部覆盖完。
所以作者还是希望读者先详细读完 kotlin 的官方文档,再结合本系列文章去理解 kotlin,以及去思考如何在 Android 开发里使用 kotlin 提高生产效率。
下面本系列正文将从 kotlin_android_base_framework 中第一个 kotlin 类进行展开讲解。
正文终于开始啦~本次内容将围绕 Model.kt 的代码,讲解 kotlin 中的 data class 以及它在 Android 开发中的一些应用。
我们可以像下面这样定义一个简单的 data 类:
data class Model(var test1: Int, var test2: Int)
data 关键字提供以下的一些 features:
按上面第三点的解释,可以理解为 test1 按照属性定义的顺序与component1() 函数对应,test2 则对应 component2()。
为什么需要 componentN() 函数呢?可以参考 Multi-Declarations 这节,主要是为了实现 多重赋值,解锁下列各种便利的写法:
val (test1, test2) = model
// 内部实现为:
// test1 = model.component1()
// test2 = model.component2()
var list = arrayListOf<Model>()
for((t1, t2) in list ) { ... }
另外,kotlin 中提供了 Pair 类来处理双元对数据,例如跳转到其他Activity 时可以这样:
val intent = intentFor<OtherActivity>(
"data" to Model(5, 0),
"data2" to "xxx"
)
intent.singleTop()
startActivity(intent)
其中 “data2” to Model(5, 0) 的等价实现其实就是:
Pair<String, Any>("data2", Model(5, 0))
data class 提供的 copy() 函数是 深度复制,其内部实现如下:
fun copy(test1: Int = this.test1, test2: Int = this.test2) = Model(test1, test2)
于是乎能够支持下面这种优雅的用法~:
val jack = User(name = "Jack", age = 1)
val olderJack = jack.copy(age = 2)
在 Android 中,Activity 之间需要传递数据通常需要对数据进行序列化,data class 就必须继承 Parcelable 或 Serializable 接口。结合我们上面的一些 points,可以对 Model 类进行如下的改造:
data class Model(var test1: Int, var test2: Int): Parcelable {
constructor(source: Parcel): this(source.readInt(), source.readInt())
override fun describeContents(): Int {
return 0
}
override fun writeToParcel(dest: Parcel?, flags: Int) {
dest?.writeInt(this.test1)
dest?.writeInt(this.test2)
}
companion object {
@JvmField final val CREATOR: Parcelable.Creator<Model> = object : Parcelable.Creator<Model> {
override fun createFromParcel(source: Parcel): Model{
return Model(source)
}
override fun newArray(size: Int): Array<Model?> {
return arrayOfNulls(size)
}
}
}
}
在上面的一坨代码中(大雾),我们先看看 data class 的构造函数。在 kotlin 的 官方文档 constructor 小结 中指定了,写在类定义头部(类名后面)的为首要构造函数 ,也就是下面这段已经构成了 data class 的类定义及 primary constructor:
data class Model(var test1: Int, var test2: Int) { ... }
而其内部显式定义的的 constructor(source: Parcel) 则为副构造函数,其传入值类型为 Parcel,返回值为 使用主构造函数构造后的 class:
this(source.readInt(), source.readInt())
翻译自 kotlin doc
不像 Java 或者 C#,在 Kotlin 中,Class 没有静态方法。在大多数情况下,推荐用 package-level 的函数来代替静态方法。
如果你需要写一个不需要实例化 Class 就能访问 Class 内部的函数(例如一个工厂函数),你可以 把它声明成 Class 内的一个实名 Object 。
另外,如果你在 Class 内声明了一个 companion object,在该对象内的所有成员都将相当于使用了 Java/C# 语法中的 static 修饰符,在外部只能通过类名来对这些属性或者函数进行访问。
而至于 @JvmField 的作用可以参考 Java Interop - Fields
至此,我们已经可以在 Android 中使用 kotlin 很轻易地定义一些我们需要的数据类,这是一次很不错的收获。下一章节,我们将提高下难度,从我们的 activity helper 讲起。
抽空把这个专栏给开张了,这是一个讲述「使用 Kotlin 进行 Android 编码」的专栏,致力于传播让 Kotlin 成为 Android 开发世界的 Swift 的(非?)异端思想。专栏作者将边学边沉淀,分享一些在使用 Kotlin 进行开发的一些心得。
另外,作者在 Github 上长期维护了一个使用 Kotlin 进行 Android 开发的实践框架 nekocode/kotlin_android_base_framework · GitHub ,它包括了一些先进的 Lib,并且尝试使用 MVP 设计模式来组织代码。大多数专栏上的代码都将抽选自该仓库,在此也希望有能力的人能够一起维护代码~ ✪ω✪
至于为什么要开专栏写这系列文章呢。作者使用 Java 进行 Android 开发已经大概有两个年头了,Java 作为一门类 C 风格传统语言难免会有很多历史包袱,相对于很多新兴的语言总感觉有些旧而沉重了,很多时候写起代码来,让人觉得很这门语言真的沉闷(特别是最近写了几个月 Python 再切回 Java)。毕竟 Java 在语法上没什么可把玩的 feature,能玩的也就那几个设计模式了。
然而,很庆幸的是得力于 Java 虚拟机大法的设计,最近一段时间衍生了一大堆现代化的 JVM 语言,而且一部分还兼容 Dalvik/ART 。它们大量纳入一些先进的语法,并将代码最终编译成字节码运行在 JVM 上(题外话:想想,SASS,CoffeeScript 的原理也相似),这同时也让开发者在 Android 开发上有了选择其他语言的可能性(Sky/Dart,Go 大法再见)。
目前比较火的 JVM 语言有 Scala,Groovy,Clojure 等,而作者为什么选择 Kotlin 呢,在作者的一些知乎回答中有提及,主要有以下两个点:
以上两点保证了 Android 开发者可以无缝从旧项目切换到 Java + Kotlin 甚至完全使用 Kotlin 的模式下。
而讲到为什么要加入 Kotlin 大军的话,当然是因为 Kotlin 语言各种先进的 Feature(详见 如何评价 Kotlin 语言? - Java )。简洁的语法,安全检测空指针,更好的 Lambda 支持,更好的函数(一级公民),泛型。更多关于 Kotlin 的介绍请看官方文档:Reference 。
本系列专栏中也会列举 Kotlin 语法上一些先进的 Feature,以及在 Android 开发中的一些应用,敬请关注~
谢邀。
王の宝库,出来吧:
讲讲第一项。别说,这可真是个宝物,知道在我的收藏夹里面怎么称呼它么?
『RxJava 操作符可视化』
什么概念?
看过官方文档里的观察流示例图片吧?好的,这就是那个的可交互版本哦!能对操作符的作用有更直接的了解。
其实是「在国内 APP 越来越难做」,个人认为有以下几个原因:
占大头的 APP 都在往平台级发展,超级 APP 功能越来越发散,逐渐侵蚀其他领域的市场。
微信,UC 浏览器此类产品开放 APP 内子产品开发平台,令 APP 开发者左右为难。就拿微信来说,很多时候,开发一款 APP 的产出投入比远远不及做公众号高,于是很大部分开发者会更倾向于开发公众号(微信用户基数大,应用内传播方便,公众号开发成本低)。
国内产品乃至创投圈风气不好,都想打擦边球,吃快餐,抄抄抄,塞塞赛,概念满天飞。『站在中国风口上的猪,还真的能飞得起来』。
在国内,知识产权就是个屁。没有绝对的技术壁垒和积累,就等着随时被巨头啃掉,所以大多数创业团队都只能跑去做巨头无法触及的领域,乃至于现在提「社交」色变。国外都是收购,并购,国内就是有好的 idea 大家一起抄,抄着抄着巨头不乐意了,也抄了起来,很多时候就变成了一场「能否在巨头之前积累足够资本」的博弈。。最蛋疼的是 idea 很多时候还是来自国外。
中国用户对应用忠诚度很低(国内产品的体验差,玩法单一等原因)
相对于美国国外的用户,美国用户对应用的忠诚度更高。在美国,被用户多次打开的应用占比今年上升了1%,至42%。这可能是由于,大量广告吸引用户重新打开已安装的应用。在美国,只被打开过一次的应用占比为19%,与去年持平。然而在美国国外,尤其是中国,应用只被打开一次的概率很高。在中国,有37%的应用只被打开过一次,远高于2014年时的26%。
说到底,是因为

我会跳街舞,Breaking。
算不上什么神技能,但确实可以算隐藏得很深了,谁会想到程序员还会跳街舞呢,而且还是最难最危险的 Breaking。。。说起为什么会学的话要从高中说起,那时和几个死党一起看了个 Breaking 的比赛视屏,看着屏幕里的人做出各种帅爆的动作,瞬间中二魂爆发,我们几个当即就立志要成为 B-boy,想着在毕业前一定要学会几个 Powermove。从此以后,每天下课和每次体育课自由活动时间,我们都到处找干净的空地,然后跟着视屏练习,甚至有几次我们还撬开了学校舞蹈室的门(拧开螺丝就能进去,出来后拧回去就是了)进去对着镜子练,后来被发现后学校换了锁就进不去了。
后来上大学,顺利加入了学院的街舞队,甚至还在学院运动会和联谊晚会上表演过。
我们舞队的照片。



但遗憾的是,大一之后就没有坚持下去了,很大的一个原因是因为大学里真正玩 Breaking 的人并不多,大多数 Dancer 玩的是难度稍低的 Popping,而且关键是再也找不到像高中那几个死党一样对 Breaking 狂热的人和我一起练习了。
把她弄成现在这样不太好吧:
AutumnsWindsGoodBye (Crying) · GitHub
虽然她技术不怎么样,但是之前她还打算建一个 Organization 来做一些国外前端文章翻译的工作,当时我也在她们 Group 里。
少点网络暴力,多点宽容吧。
===
问题的 “为什么有人GitHub排行很低,不仅不向排行高的学习,反而去黑排行高的?” 会不会给人一种 排名高就代表技术好的钦定的感觉?
说实话,
@秋风
的技术真不怎么样,用机器人 follow 别人来刷粉的行为也有不妥。不过想想,刷粉的人大有人在,大多数当初反 follow 她的人更可能是因为她是个妹子而且头像美,和她技术没多大关系(逃。。
其实她只是个很会运营(Github,知乎,甚至 QQ 群)的懂点前端的长得还可以的妹子而已。不过想想,你们 follow 她的时候还不都是因为她的(给自己挂的)程序媛标签,现在怎么反过来黑别人的技术了。
首先,题主的出发点是完全错误的。既然题主自认为技术很扎实,那你就不应该一开始就想着如何造假,而应该考虑如何弱化简历上自己短板(项目经验),突出自己的强项,体现自身的价值。其次,没有职业道德的人无论到哪(包括知乎)都是不受欢迎的。你在这提问如何造假,只会成为嘲讽 or 被攻击对象。
自身短板的形成必然是有原因的,把所有原因都归咎到其他事物身上(老东家),这是对自己极其不负责任的表现。公司项目不怎样,但是利用自己空余时间投身到写博客或开源项目中的人也大有人在啊,别人在恶补自己短板的时候题主又在干些什么,。。
让人发现你伪造履历的话,肯定是进企业黑名单的,希望你能慎重考虑下。哪怕你真的造假去面试,但是最后可能会发现其实问题不出在这,你还是只值这个价。至少我们公司是不会请这种人,更别谈值什么价了。
首先, Visual Studio 先用各种领先 IDE 技术吸引大批 Android 开发者。然后,,就可以鼓吹开发者,以低成本将 Android 应用迁移到 Windows Phone 系统上啦。
navie
不显示 UAC 窗口的话(bypass UAC)必须使用 hack 的方法:
nishang/Invoke-PsUACme.ps1· GitHub
或者参考下我写的渗透脚本(bat & ps1):
nekocode/win_penetration · GitHub
可以绕过 UAC 获取管理员权限。但是里面有很多其他危险操作,不要乱试。
==== 想知道 bypass 原理的话可以评论下,我再补上 ====
如果是简单的数据处理的话,我会用 @justjavac 答案里的做法:直接在 rendering 里处理数据。但是如果是计算密集的处理的话,我建议用 useMemo:
const { data: data1 } = //...
const parsedData1 = useMemo(
() => data1?.data ? JSON.parse(data1.data) : undefined,
[data1]);
另外,如果答主一定要维护额外的 state 的话(例如在其他地方需要改变 state),那就把你那个大的 useEffect 拆分成四个小的 useEffect 吧。
再假设你想要等四个请求都完成再 setState 的话,可以:
const dataRef = useRef([data1, data2, data3, data3]);
dataRef.current = [data1, data2, data3, data3];
const isDone = data1?.data && data2?.data && data3?.data && data4?.data;
useEffect(() => {
if (isDone) {
setState1(dataRef.current[0]);
setState2(dataRef.current[1]);
setState3(dataRef.current[2]);
setState4(dataRef.current[4]);
}
}, [isDone])
这里只是提供思路,换我的话我是不会用四个 state 来维护状态。
写了一个多月 Flutter 后的感受:基本支持 @千里冰封 你懂吗 回答里的大部分观点(除了关于 Gradle 相关的描述外,狗头)。Dart 是个不坏的选择,但绝对不是最好的选择(这里抛开商业相关的顾虑)。Dart 作为一门现代编程语言,比起老前辈 Js、Java 来说确实「智慧」了不少,但是对比起 TypeScript、Kotlin 还是差得远,以至于给我一种高不成低不就的感觉(或许是 Kotlin 确实太优秀了)。而 IDE 的支持即使迭代到目前依旧问题很多(不够智能、经常报错信息位置不对),但这个也确实怪不了 Google,论 IDE 技能 Jetbrains 是吊打 Google 级别的。
个人猜测 Flutter 很长一段时间不会选择支持其他语言,更不可能抛弃 Dart。我个人很喜欢 Flutter,它还原 UI 的速度比 Android 快很多很多,但是 Dart 让它稍微逊色了一点点,目前我只希望 Dart 以及周边能随着 Flutter 的推广进步得更快一些。
提一个,Android Studio 自带的 Profiler 还不够好用,例如:
不问是不是,就问为什么。
绝大部分长得丑的人都不自恋,只是长得丑而又自恋的人显得格外突出而已。
流行的有两种方案:
1. 明转义
这是很多 SNS 网站的做法(例如新浪微博、知乎):
@+用户昵称+空格(也可以为其他用户名称中禁止的字符)
这种方法的局限在于:
2.暗转义
大部分即时聊天工具有这种(例如 QQ、Wechat),它的一个原始形式如下:
转义开始符+UID+转义结束符
经过 UI 层转义后向用户显示的是:
@+用户昵称
这种方法的好处在于:
坏处在于实现起来比明转义稍微复杂一些。
应该如何选择?
个人认为应该尽量使用 useMemo 和 useCallback。
所有 rendering 中创建的 callback 尽量用 useCallback 包起来、对象的创建尽量用 useMemo 包起来。
hooks 具有依赖传递性,这么做主要是为了避免触发可能隐藏在某个子组件里的多余的副作用,以及副作用最终可能造成的 re-render(甚至死循环)。
试想一下你写了个组件,props 里需要传进一个 callback 来响应 dom 事件。一开始不用 useCallback 可能没问题,但是某天当你突然要改成在 useEffect 里去响应这个 callback 的话那就崩了,你不得不把上层所有组件传参时都用 useCallback 包一下,如果你这个组件在很底层,那么扩散范围将特别大,更不说跨 package 这种更糟糕的情况了。
这类情况还是很常见的,为了减少心智成本(对于究竟要不要/能不能用的患得患失)、以及不必要的埋坑,尽量使用 useMemo 和 useCallback 很有必要。
非专业前端工程师,发表些业余看法:
Vue 是传统的在 Html 里写 Js,而 React 则是在 Js 里写 Html。(题外话:作为一个 Android 工程师,感觉这有点像 Databinding 和 Anko 之间的差异)
Vue 的好处是非侵入,不需要重构,在原有的 Html 和 Js 基础上改就行了。React 的话则更可能需要大面积重构整个项目。
论上手简单的话,对于前端工程师应该 Vue 确实会更容易一些吧?毕竟思维上不需要做什么转变。但是对于零基础的人,感觉其实差不多,个人喜欢 React 多些。
Hybrid?效率已经不是问题?
自欺欺人,HTML 实现一个 Android 抽屉就卡出翔来。
HTML5 的优势在于排版,要做出相同效果的 Native 界面排版成本太大,所以内容展示页可以考虑使用 Hybrid 开发。逻辑关系复杂的页面还是老老实实用 Native 开发吧。
React Native?
还早着呢,Virtual DOM 对于需要复杂更新的页面一样显得乏力。这东西确实可以关注,热更新对于 Native APP 来说就是硬伤,React Native 不仅很好地解决了跨平台问题,还解决了热更新问题。
至于纯 HTML5 APP?
个人觉得不是很重度的 APP 都可以用 H5 来做,开发 Android 和 iOS 端的成本太高。现在不是还有 微信,公众号等平台么。
මම ඔබට කියන්න අවශ්ය, මම ඔයාට ආදරෙයි
试试复制第一行的,android 系统下无法正常显示的。
至于为什么无法显示是因为系统没装这种语种的字体文件,无法得知该类字体该如何渲染。打个比方,如果某美国人手机系统的字体库里只安装了英文字体的话,那么他们看中文也会无法正常显示。