背景
知乎 Android 客户端作为一个比较大型的应用,由于功能不断地迭(zeng)代(jia),启动速度也会受到影响,为了提升用户体验,知乎移动平台团队把提高 App 启动速度定为了的一个长期而且重要的 OKR,于是我们在今年的第二季度,重点对客户端的启动做了一系列的优化。
虽然在性能优化相关领域我们还处于刚开始的阶段,但是在优化过程中我们还是总结出了一些经验可以拿出来分享。所以,今天我们来分享其中一次和 Retrofit 相关的优化经历。
开始之前
我们在做性能优化时,很多人可能苦恼于怎么去检验或者说量化最终优化的效果。这里面其实是有学问的,通常我们会选用系统输出的信息来作为指标,例如众所周知的用 GPU 渲染柱状图来作为 UI 是否卡顿的指标。为什么要选系统输出的信息?一来采集更方便,不需要自己写代码去测量,二来是我们还能采集到其他 App 的信息,方便与其他竞品做横向对比。
而启动速度的话,我们会选用系统打印的 Activity 启动 Log 作为指标:
107-11 15:09:32.519 1440-1502/? I/ActivityManager: Displayed com.zhihu.android/.app.ui.activity.MainActivity: +1s412ms (total +1s978ms)
Log 数据的含义可以看 Stack Overflow 上的这个 回答
,我们主要取 App 冷启动到第一个 Activity 显示出来的时间。
言归正传,在这次优化开始之前,为了能和最终的数据做对比,我们需要先测出 App 优化前的启动时间。通过对 App 进行多次冷启动并记录 Log 里的 Total duration,得出了 App 在优化前的平均启动时间为 1.905s(数据来自 OnePlus 3T):

Log 输出
发现 & 分析问题
我们想要找究竟是哪些代码导致启动变慢,光靠 Review 代码是做不到的,因为一段代码的执行效率除了受各种内因(CPU / IO 操作密集,锁…)的影响,还有可能受其他外因(系统资源争夺、GC…)的影响。所以想要快速准确地找出问题,最好的方法是让代码真正执行起来,然后去 Profile(监测)代码运行时的情况。
而 Profiling 其实是一门很大的学问,需要用到大量的工具,包括 Android 系统、SDK、甚至 IDE 提供的一些接口或工具,熟练运用这些工具去分析和发现性能问题是做性能优化的必备技能。而针对今天知乎 App 启动的 Profiling,我会简单介绍其中一部分的工具:
Method Tracing
Method Tracing,就是跟踪 App 某段时间内所有调用过的方法,这是测量代码执行性能常用的方式之一,我们可以通过它来查出 App 启动时具体都调用了方法,都花了多长时间。
这个功能是 Android 系统提供的,我们可以通过在代码里手动调用 android.os.Debug.startMethodTracing() 和 stopMethodTracing() 方法来开始和结束 Tracing,然后系统会把 Tracing 的结果保存到手机的 .trace 文件里。详情可以看 官方文档
。
此外,除了通过写代码来 Trace,我们也有更方便的方式。例如也可以通过 Android Studio Profiler 里的 Method Tracer 来进行。但是,针对 App 的冷启动,我们则通常会用 Android 系统自带的 Am 命令来进行,因为它能准确的在 App 启动的时候就开始 Trace:
# 启动指定 Activity,并同时进行采样跟踪
adb shell am start -n com.zhihu.android/com.zhihu.android.app.ui.activity.MainActivity --start-profiler /data/local/tmp/zhihu-startup.trace --sampling 1000
当 App 冷启动完毕后(首个 Activity 已经绘制到屏幕上),使用以下命令手动终止跟踪,并拉取 .trace 文件到本机的当前目录下:
# 终止跟踪
adb shell am profile stop
# 拉取 .trace 文件到本机当前目录
adb pull /data/local/tmp/zhihu-startup.trace .
拿到 .trace 文件之后,下一步就是进行可视化了。可以直接拖动 .trace 文件到 Android Studio 里打开,但 Android Studio 目前版本对 .trace 文件的可视化和交互做得还不怎么样,所以不推荐。在这里推荐使用 Android Device Monitor 里的 Traceview 来打开,详情可以查阅 官方文档
。
用 Traceview 打开之后的截图:
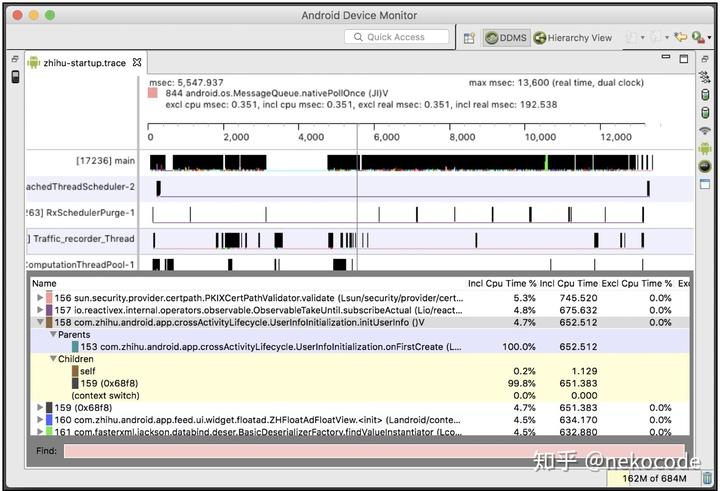
Traceview 截图
所有跟踪到的方法会默认按照实际总耗时从多到少向下排序,点击某个方法可以看到它的所有父调用方法和子调用方法。通过从上往下一条条排查,可以看到在知乎 App 启动时 UserInfoInitialization 类的 initUserInfo() 方法竟然耗时超过 600ms:

initUserInfo() 方法

159 (0x68f8) 方法
我们来看看这个 initUserInfo() 方法的代码:
private void initUserInfo() {
NetworkUtils.createService(ProfileService.class)
.getSelf(AppInfo.getAppId())
// ...
.subscribe(response -> {
// ...
}, Debug::e);
}
NetworkUtils.createService() 是我们自己封装的一个方法,内部调用 Retrofit 来获取 ProfileService 的动态代理类,而 getSelf() 则是动态代理类提供的一个方法。从 Traceview 中可以看到,159 (0x68f8) 这个是运行时生成的代理方法,所以可以判断这里的耗时是因为调用 getSelf() 引起的。
继续往下跟踪:

responseBodyConverter() 方法

_newReader() 方法
可以看出来,最终主要的耗时在 Jackson 库的几个方法上,而 Jackson 库是我们是用来给 Retrofit 序列化和反序列化数据(例如 Response Body)用的。
接下来就是深入追查原因了。通过查看 Retrofit 的代码可以知道,在第一次调用 Retrofit 的某个动态代理方法时,Retrofit 会新建一个 ServiceMethod 实例来储存该代理方法相关的一些数据,包括一个用来转换 Response Body 的 Converter。而在新建这个 Converter 的时候,则会根据 Body 反序列化结果对应的 Java Model 类来生成一个 ObjectReader,如果对应的 Java Model 类特别复杂,那么新建 ObjectReader 的时间也会特别长(内部会进行一堆反射操作)。而恰恰我们 getSelf() 方法返回的 Java Model 是一个字段极其多的类,所以造成第一次调用该代理方法时特别耗时。
问题的原因我们已经通过 Method Tracing 找到了,接下来我们可以通过另外一个工具来看看问题发生时,App 和系统的真实情况。
Systrace
Method Tracing 虽然是找出耗时方法的利器,但是执行 Method Tracing 时会严重拖慢 App 的执行速度,即便使用采样跟踪,测量得到的结果和实际结果肯定还是有很大偏差,只能作为参考。而且 Method Tracing 对锁、GC、资源匮乏等其他因素的追查显得十分无力。所以,我们可以借助另一个 Google 官方极力推荐的工具 -「Systrace」来跟踪 App 实际运行时的情况。详细介绍可以查看 官方文档
。
Systrace 的原理是通过 Android 系统自带的 atrace 工具来捕获系统以及 App 的一些关键信息,然后通过 Chrome 浏览器来进行可视化。
接下来,我们将通过 Systrace 来跟踪知乎 App 在启动时执行 Retrofit 代理方法的整个过程。首先,我们需要做一些准备:
- 为了让结果更接近真实情况,我们需要为 Release 包开启 App Tracing 的功能,详情可以查看 这里
。
- 给 Retrofit 的 loadServiceMethod() 方法添加 Tracing Section(PS:可以借助 JarFilterPlugin
来修改 Retrofit 的内部代码):
ServiceMethod<?, ?> loadServiceMethod(Method method) {
Trace.beginSection("Retrofit:" + method.getName());
// ...
Trace.endSection();
return result;
}
- 添加 Proguard 规则,保证 method.getName() 获取到正确的方法名:
-keepclassmembernames class * {
@retrofit2.http.GET *;
@retrofit2.http.POST *;
@retrofit2.http.PUT *;
@retrofit2.http.DELETE *;
}
做完准备后用 Gradle 命令打出一个上线标准的 Release 包并安装上手机,然后就可以开始用 Systrace 来跟踪了:
systrace -a com.zhihu.android app view res am sched dalvik
开始跟踪后,冷启动 App,等到首个 Activity 可见之后点击回车结束跟踪。跟踪结束后 Systrace 会把跟踪结果保存到当前目录下的 trace.html 文件,使用 Chrome 打开后:
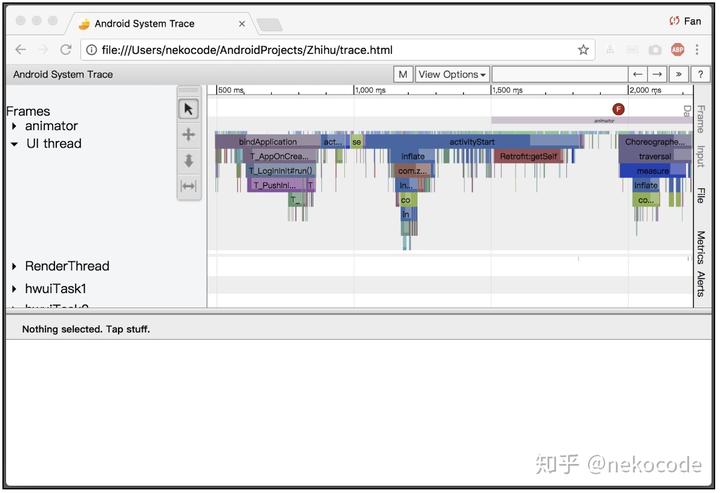
Chrome 截图
通过 Chrome 可以很直观地看到 App 在启动时的各种关键的 Section。此外,我们还能看系统 CPU 每个时期的使用率以及每个核心上执行的线程:
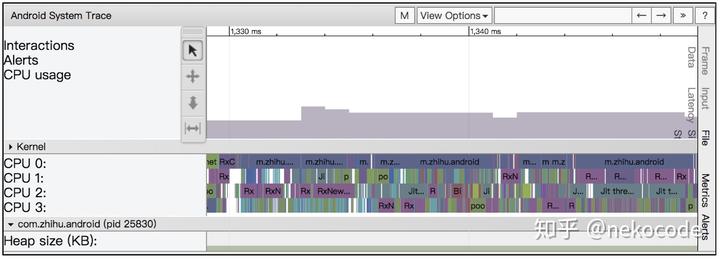
CPU 使用率和每个核心上执行的线程
通过选定某个线程上面的线程状态条,我们可以查看某段时间或 Section 里线程的运行状态:
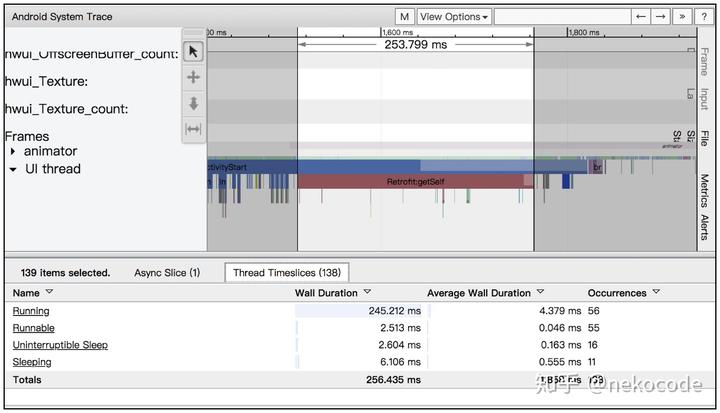
线程状态
从上图可以看出,在「Retrofit:getSelft」这个 Section 里,UI Thread 基本都是 Running 状态,说明 getSelft() 内部执行的都是 CPU 密集的操作,很少进入等待状态。这也说明了 getSelft() 方法的耗时是实打实的,不是由于其他原因(例如锁等待)造成。而且有一点需要注意,这里测出来的实际耗时是 250 多毫秒,而 Method Tracing 测量出来的耗时是 650 毫秒,由此可以看出 Method Tracing 的测量结果误差还是很大的。
接着我们通过搜索「Retrofit:」关键字可以看到,在启动期间会不止一次调用到 Retrofit 的 loadServiceMethod() 方法:

搜索结果
而且有很多还是在 UI 线程上调用的,但是其实这些操作没必要放在 UI 线程上,我们需要想办法把所有 loadServiceMethod() 的调用都扔到其他线程上。
解决问题
耗时的原因已经找到了,而优化的思路就是把 loadServiceMethod() 的调用扔到非 UI 线程上。例如,针对 getSelf() 这个方法,我们可以使用 Observable 的 defer() 操作符把它放到非 UI 线程上去异步执行:
private void initUserInfo() {
Observable.defer(() ->
NetworkUtils.createService(ProfileService.class).getSelf(AppInfo.getAppId())
.subscribeOn(Schedulers.io())
)
.subscribeOn(Schedulers.single())
// ...
.subscribe(response -> {
// ...
}, Debug::e);
}
这是针对单处地方的改法,但要知道,启动的时候不单单只有这一处会调用到 Retrofit 的 loadServiceMethod(),要把所有地方都加上 defer() 操作符的化修改量有点大。所以有没有更好的办法呢?
答案就是二次动态代理:
public final class Net {
public static <T> createService(Class<T> service) {
// ...
return createWrapperService(mRetrofit, service);
}
private static <T> T createWrapperService(Retrofit retrofit, Class<T> service) {
return (T) Proxy.newProxyInstance(service.getClassLoader(),
new Class<?>[]{service}, new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, @Nullable Object[] args)
throws Throwable {
if (method.getReturnType() == Observable.class) {
// 如果方法返回值是 Observable 的话,则包一层再返回
return Observable.defer(() -> {
final T service = getRetrofitService();
// 执行真正的 Retrofit 动态代理的方法
return ((Observable) getRetrofitMethod(service, method)
.invoke(service, args))
.subscribeOn(Schedulers.io());
})
.subscribeOn(Schedulers.single());
}
// 返回值不是 Observable 的话不处理
final T service = getRetrofitService();
return getRetrofitMethod(service, method).invoke(service, args);
}
// ...
});
}
}
原理就是再创建一层动态代理,然后把底层 Retrofit 代理方法的调用包进新的 Observable 里再返回。这么改的好处是可以一劳永逸,让所有调用的地方无需做任何更改,减少了代码的修改量。
经过这么优化之后,我们重新测试了一遍启动时长,最终得出优化后的启动时间大概快了 400ms。可以看出,这次优化是成功的。
结语
我们这次优化经历到这里就结束啦,可以看到我们整篇文章里的「发现 & 分析问题」这一章占的篇幅是最大的,这其实也反映了我们在做性能优化时的常态,大多数时间都会花在 Profiling 上,当遇到优化瓶颈时,更可能花大量时间去通过各种工具抽丝剥茧地分析问题。
其实上面也讲到了,Profiling 是一门大学问,本次分享只是挑了些比较简单但是关键的方式和工具来讲,实际在进行 Profile 的时候会用到更多的知识,有时候甚至需要自己写工具去辅助定位问题。希望本篇文章能起到抛砖引玉的作用,让大家能了解到做启动优化时的一些常用思路。此外,该次只是我们优化知乎 Android 客户端启动速度的其中一次经历,知乎移动平台团队还在不断地为优化启动速度做努力~也希望未来还能分享更多的经历给大家。
由于本人的水平有限,如有错误和疏漏,欢迎各位同学指正。
另外,知乎移动平台团队也在招人中,欢迎各位小伙伴的加入,和我们一起做一些酷事情!具体招聘信息在这里 https://app.mokahr.com/apply/zhihu#/job/7b1b32c2-f30c-4638-93ce-09c2ac9a52d8